1. IT 관련 기사를 스크래핑
네이버 IT 카페고리 뉴스 기사의 헤드라인 뉴스를 뽑는다
https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105
IT/과학 : 네이버 뉴스
모바일, 인터넷, SNS, 통신 등 IT/과학 분야 뉴스 제공
news.naver.com
태그 추출은 지난 블로그를 토대로 진행한다.
2024.01.13 - [Python] - 웹 스크래핑으로 뉴스 기사 링크 받아오기
웹 스크래핑으로 뉴스 기사 링크 받아오기
웹스크래핑을 이용하여 IT 관련 뉴스를 보기 위한 코드입니다 웹 스크래핑 내용 2024.01.13 - [Python] - 웹 스크래핑 웹 스크래핑 웹크롤링: 웹사이트에서 URL, 키워드 수집(검색엔진이 웹사이트를 인
dogfoot1.tistory.com
2. 스크랩한 날짜, 기사 제목, 기사 링크, 기사 내용을 엑셀에 넣는다
1. 필요 라이브러리 임포트
#셀레니움 관련 라이브러리
from selenium import webdriver
from selenium.webdriver.common.by import By
#엑셀 관련 라이브러리
from openpyxl import Workbook, load_workbook
import os
#날짜 관련 라이브러리
import datetime
2. 크롬 웹드라이버 생성
driver = webdriver.Chrome()
driver.implicitly_wait(3)
driver.get("https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105")
3. 엑셀 워크북 생성/불러오기
#경로에 파일이 없다면
if not os.path.isfile("경로/뉴스.xlsx"):
#엑셀 워크북 생성
wb = Workbook(write_only=True)
ws = wb.create_sheet('IT 뉴스')
#날짜, 뉴스 기사 제목, 링크, 본문 내용
ws.append(['날짜', '뉴스 제목', '링크', '본문 내용'])
#경로에 파일이 있다면
else:
wb = load_workbook('경로/뉴스.xlsx')
ws = wb['IT 뉴스']
if not os.path.isfile() 사용
[04-5] Python - 파일 존재(isfile), 디렉토리 존재(isdir) 확인 방법
python 뿐만 아니라 코딩을 하다보면 특정 디렉토리의 존재 여부, 혹은 특정 파일의 존재여부를 확인해야 할 경우가 종종 존재한다. 이 때에는 해당 디렉토리, 파일 존재 여부를 확인하는 API를 사
technote.kr
4. 숨겨진 헤드라인 뉴스가 있기 때문에 더보기 버튼 클릭


#헤드라인 뉴스 더보기 클릭
driver.find_element(By.CSS_SELECTOR, 'a.cluster_more_inner').click()
5. 스크롤을 하기
(더보기 버튼을 클릭해서 맨 위의 헤드라인 뉴스 기사가 화면을 벗어나기 때문에)
driver.execute_script('window.scrollTo(0,0)')
6. 8개의 헤드라인 뉴스 수집
혹시 모를 오류를 위해 예외처리를 한다
#8개 헤드라인 뉴스 수집
for num in range(len(driver.find_elements(By.CSS_SELECTOR, 'li.sh_item div.sh_text>a'))):
#기사 보기
try:
news = driver.find_elements(By.CSS_SELECTOR, 'li.sh_item div.sh_text>a')[num]
#기사 제목
title = news.text
#print(title)
#기사 링크
link = news.get_attribute('href')
#print(link)
#기사 본문 클릭
news.click()
content = driver.find_element(By.CSS_SELECTOR, 'article#dic_area').text
#print(content)
#엑셀에 넣기
ws.append([date, title, link, content])
#뒤로 가기
driver.back()
except:
pass
7. 웹드라이버 종료 및 엑셀 저장
driver.quit()
wb.save('뉴스.xlsx')
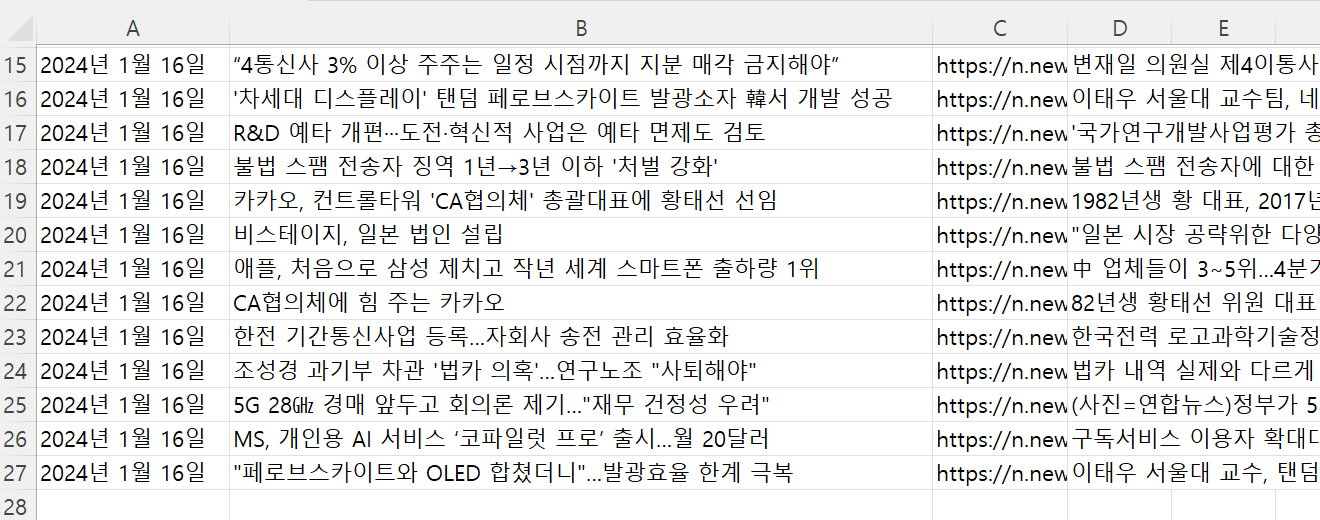
결과
오류 프로파일링
1. ElementClickInterceptedException 오류
더보기 클릭 후 첫 번째 요소(첫 번째 기사)를 클릭하려고 할 때 오류 발생
이유: 요소가 가려지거나, 화면을 벗어나기 때문에

https://wise-office-worker.tistory.com/63
파이썬 셀레니움 ElementClickInterceptedException 해결방법
파이썬에서 버튼의 클릭 또는 텍스트 입력을 위해서는 웹 엘리먼트를 클릭해야 합니다. 하지만 구글 애드센스 광고나 기타 엘리먼트들에 의해서 대상 엘리먼트가 가려지는 원인으로 ElementClickIn
wise-office-worker.tistory.com
해결법 -> 요소를 클릭할 수 있도록 스크롤을 한다
저는 맨 위로 스크롤 하여 첫 번째 요소를 화면에 보여주는 방법으로 해결했습니다
driver.execute_script('window.scrollTo(0,0)')
2. StaleElementReferenceException 오류
오류 코드
for news in headline_news:
#기사 제목
title = news.text
#기사 링크
link = news.get_attribute('href')
#기사 본문 클릭
news.click()
content = driver.find_element(By.CSS_SELECTOR, 'article#dic_area').text
#뒤로 가기
driver.back()
새 탭이 생기지 않고, 원래 탭에서 다른 사이트가 나타날 때 driver.back()으로 다시 돌아오면
for문이 제대로 동작하지 않는다(새로고침도)
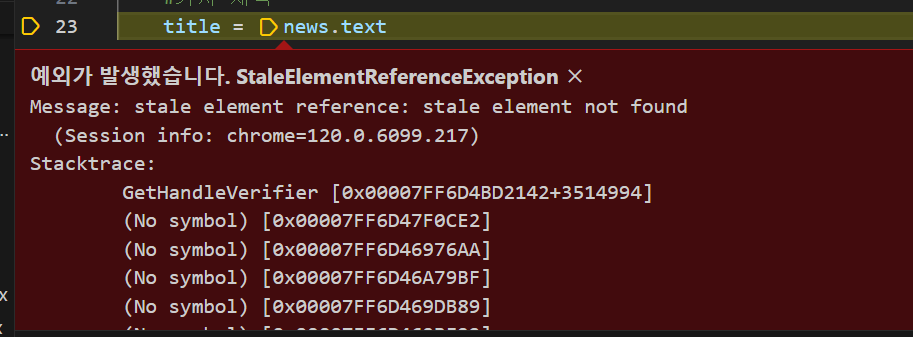
이유: driver.back()을 할 경우 기존에 가지고 있던 요소 정보를 잃어 버리기 때문!
해결법 -> 요소를 다시 찾아야 한다
for문에서 창 전환 후 에러 해결 방법 문의 - 인프런
from selenium import webdriver # webdriver 불러오기from selenium.webdriver.chrome.options import Options # 브라우저 닫힘 방지from selenium.webdriver.chrome.service ...
www.inflearn.com
파이썬 Selenium StaleElementReferenceException 오류
StaleElementReferenceException은 요소가 더 이상 DOM에 존재하지 않거나 업데이트된 경우에 발생하는 오류입니다. 웹 페이지가 변경되거나 요소가 업데이트될 때 발생할 수 있습니다. 예시 코드와 해결
workauto.tistory.com
저는 for문을 find_elements의 길이만큼 돌고, 인덱스를 사용하는 방법으로 해결했습니다
# 길이만큼
for num in range(len(driver.find_elements(By.CSS_SELECTOR, 'li.sh_item div.sh_text>a'))):
# find_elements() 다시 하고, index로 접근
news = driver.find_elements(By.CSS_SELECTOR, 'li.sh_item div.sh_text>a')[num]
+ 그 외 셀레니움을 사용하면서 만나는 오류들
https://cat-minzzi.tistory.com/28
[파이썬으로 웹스크래핑] 에러? 또 에러?! 셀레니움으로 막힘 없이 스크랩하기
내가 앞에서 쓴 글, 혹은 다른 곳에서 셀레니움을 동작하는 방법을 익힌 분들이 셀레니움이 특정 페이지에서 요소를 못찾거나 하는 이유로 프로그램 자체가 정지해버려 다시 처음부터 자료를
cat-minzzi.tistory.com
try, except 문을 잘 활용합시다!
'Python' 카테고리의 다른 글
| [Python] 힙 (1) | 2024.02.05 |
|---|---|
| 웹 스크래핑으로 인기 급상승 동영상 데이터 저장하기 (1) | 2024.01.22 |
| Selenium 사용하여 웹 자동화하기2 (1) | 2024.01.16 |
| Selenium 사용하여 웹 자동화하기1 (0) | 2024.01.15 |
| 웹 스크래핑으로 뉴스 기사 링크 받아오기 (0) | 2024.01.13 |