웹스크래핑을 이용하여 IT 관련 뉴스를 보기 위한 코드입니다
웹 스크래핑 내용
2024.01.13 - [Python] - 웹 스크래핑
웹 스크래핑
웹크롤링: 웹사이트에서 URL, 키워드 수집(검색엔진이 웹사이트를 인덱싱하기 위해) 웹스크래핑: 웹사이트에서 필요한 데이터 긁어오기 VsCode 터미널에서 파이썬 가상환경 만들기 라이브러리 간
dogfoot1.tistory.com
네이버 뉴스의 IT/과학 분야의 헤드라인 뉴스의 제목과 기사 링크를 받아옵니다
https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105
IT/과학 : 네이버 뉴스
모바일, 인터넷, SNS, 통신 등 IT/과학 분야 뉴스 제공
news.naver.com
필요 라이브러리 임포트
import datetime
import requests
from bs4 import BeautifulSoup
html 코드 받아오기
response = requests.get("https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
날짜 출력하기
d = datetime.datetime.now()
print(f"<{d.year}년 {d.month}월 {d.day}일 IT 과학 헤드라인 뉴스>\n")
필요한 태그 찾기
마우스 우클릭 -> 검사 클릭 혹은 F12 누르면
개발자 도구가 나옵니다

왼쪽 상단의 아이콘 클릭하면 웹 사이트의 html 태그를 확인할 수 있습니다
헤드라인 뉴스들은 ul 태그에 구성되어 있습니다
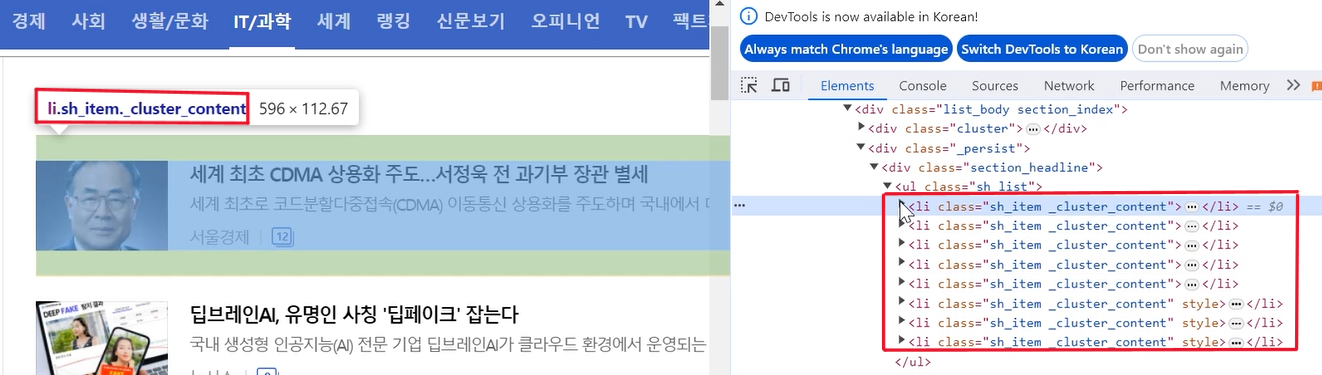
ul 태그 안을 보겠습니다
하나의 헤드라인 뉴스에 하나의 li 태그로 이루어져 있습니다

class는 sh_item, _cluster_content인 li태그를 살펴보겠습니다
class가 sh_thumb인 div 태그는 사진인 듯 합니다

class가 sh_text인 div 태그에 제가 찾을 기사 제목이 있는 것 같습니다
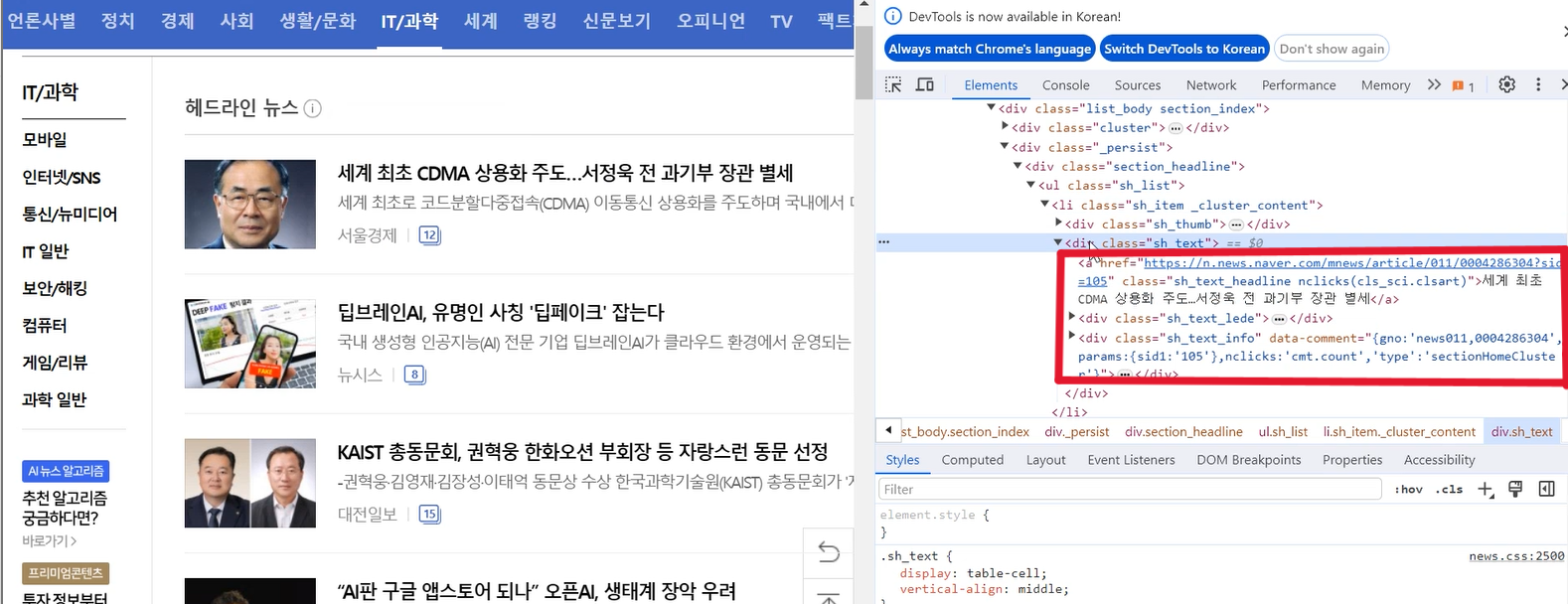
class가 sh_text인 div 태그를 살펴보겠습니다
a태그와 div 태그 두 개가 있습니다
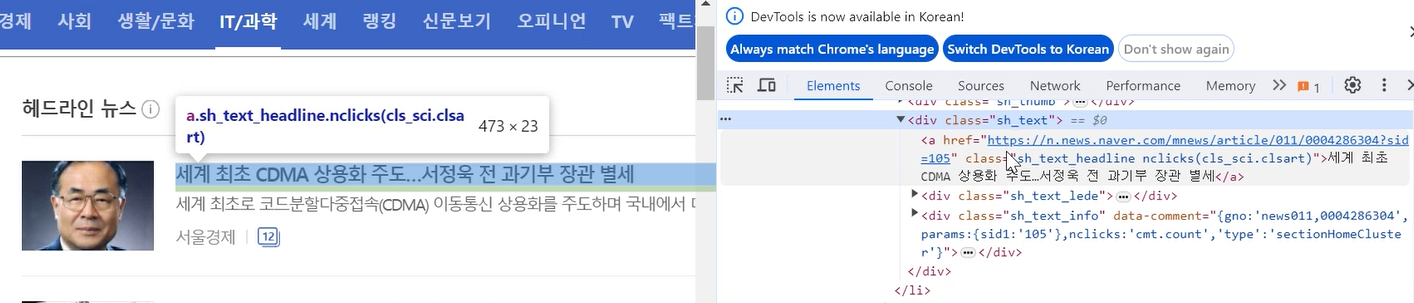
a 태그에 제가 찾던 기사 제목과 기사 링크가 있네요
기사 제목은 a 태그의 텍스트만 추출하면 되고,
기사 링크는 a 태그의 href 속성을 추출하면 되겠습니다.
title = soup.select('li.sh_item div.sh_text>a')
for tag in title:
print(tag.get_text())
print(tag['href'])
print()class가 sh_item인 li태그 안에
class가 sh_text인 div 태그의 자식 중
a 태그를 select했습니다
리턴된 리스트를 for문을 돌리면서 텍스트와 href 속성의 값을 출력합니다
+
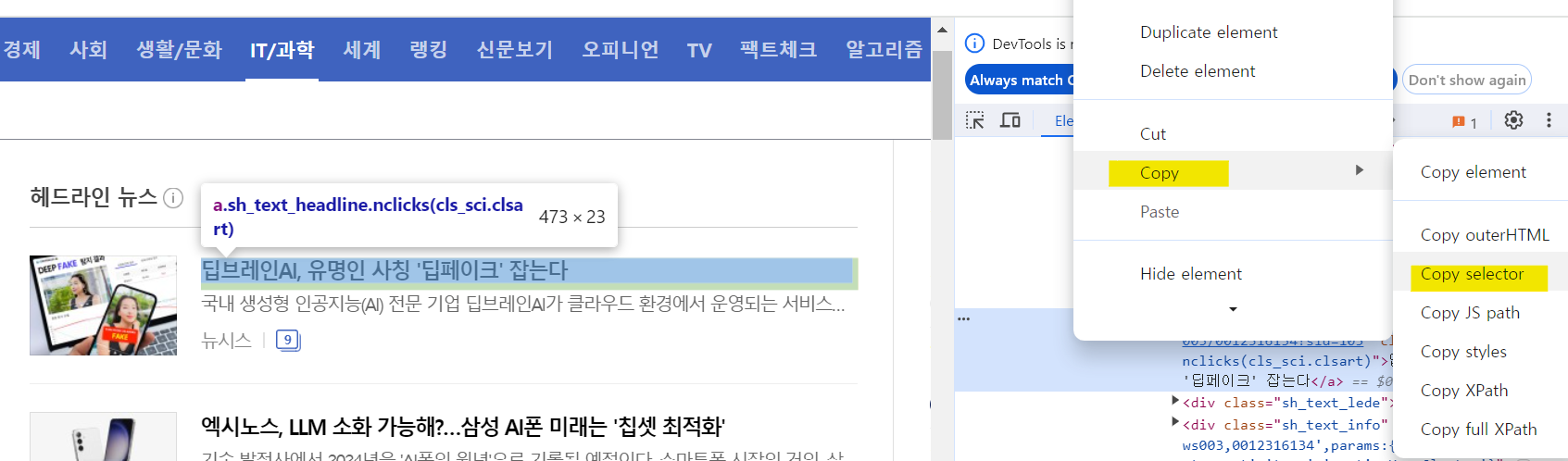
사실 원하는 HTML 태그에 오른쪽 마우스를 클릭하고 Copy > Copy selector을 해도 됩니다
#main_content > div > div._persist > div.section_headline > ul > li:nth-child(1) > div.sh_text > a
그럼 이렇게 자식에 자식에 자식을 타고 CSS 선택자를 선택해줍니다
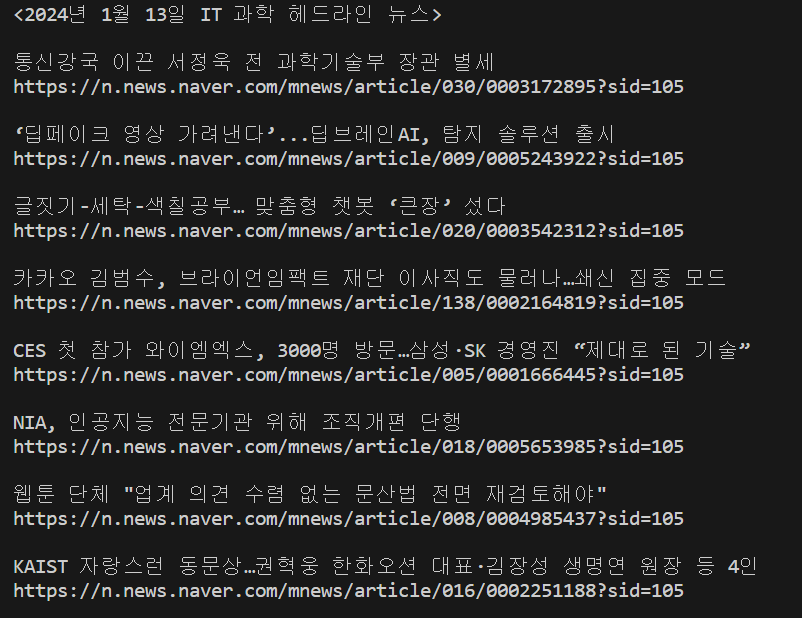
참고로 헤드라인 뉴스는 배열 순서는 개인화를 반영해 자동 제공되어 새로고침 할 때마다 달라집니다(웹 사이트에서 보이는 것과도 순서가 다를 수 있음)
'Python' 카테고리의 다른 글
| Selenium 사용하여 웹 자동화하기2 (2) | 2024.01.16 |
|---|---|
| Selenium 사용하여 웹 자동화하기1 (0) | 2024.01.15 |
| Python에서 엑셀, csv 다루기 (1) | 2024.01.13 |
| 웹 스크래핑 (1) | 2024.01.13 |
| 알고리즘 패러다임 (0) | 2023.11.18 |