저는 유튜브 인기 급상승 동영상을 1시간마다 업데이트하여
50만회 이상인 동영상의 정보만 엑셀에 저장해보겠습니다!
필요 라이브러리를 임포트
#웹 스크래핑
from selenium import webdriver
from bs4 import BeautifulSoup
#엑셀
from openpyxl import Workbook, load_workbook
import os
import pandas as pd
import datetime
엑셀 워크북 생성/불러오기
if not os.path.isfile("유튜브인기급상승동영상.xlsx"):
#엑셀 워크북 생성
wb = Workbook(write_only=True)
ws = wb.create_sheet('인기급상승동영상')
#컬럼 정보
ws.append(['시간', '영상 제목', '게시자', '영상 링크'])
else:
wb = load_workbook('유튜브인기급상승동영상.xlsx')
ws = wb['인기급상승동영상']
크롬 웹 드라이버 생성
#크롬 웹 드라이버 생성
driver = webdriver.Chrome()
driver.implicitly_wait(3)
driver.get("https://www.youtube.com/feed/trending?app=desktop&gl=KR&hl=ko")
BeautifulSoup으로 HTML 소스 받기
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit()driver.page_source를 사용하여 html 소스를 받고 driver을 종료합니다
requests 라이브러리로 html 소스를 받아오지 않는 이유?
requests는 초기 html 소스만 가져오고,
selenium 라이브러리 모든 html 소스를 가져오기 때문에 selenium을 사용한다

https://dodonam.tistory.com/371
[크롤링] What is the differences between requests and selenium?
웹크롤링 중에 request를 써서 html을 불러왔는데 간혹 내가 수집하려는 데이터가 없는 경우가 있다? 이럴 경우, 당황하지말자. 그것이 requests의 한계 requests - 웹페이지의 상태를 가져오는 것으로
dodonam.tistory.com
태그 추출
text_tags = soup.select('div#dismissible div.text-wrapper div#meta')동영상에 대한 정보가 있는 태그를 추출합니다
조회수를 추출하고 숫자 형태로 변환
for txt in text_tags:
#'조회수 n만회' 형태
#'조회수 n억회' 형태
views = txt.select_one('div#metadata-line span').get_text()
views = views.split()[1]
views = views.replace('만회', '0000')
views = views.replace('억회', '00000000')
50만회 이상인지 체크
if int(views) >= 500000:
a_tag = txt.select_one('div#title-wrapper h3 a')
#제목
title = a_tag['title']
#게시자
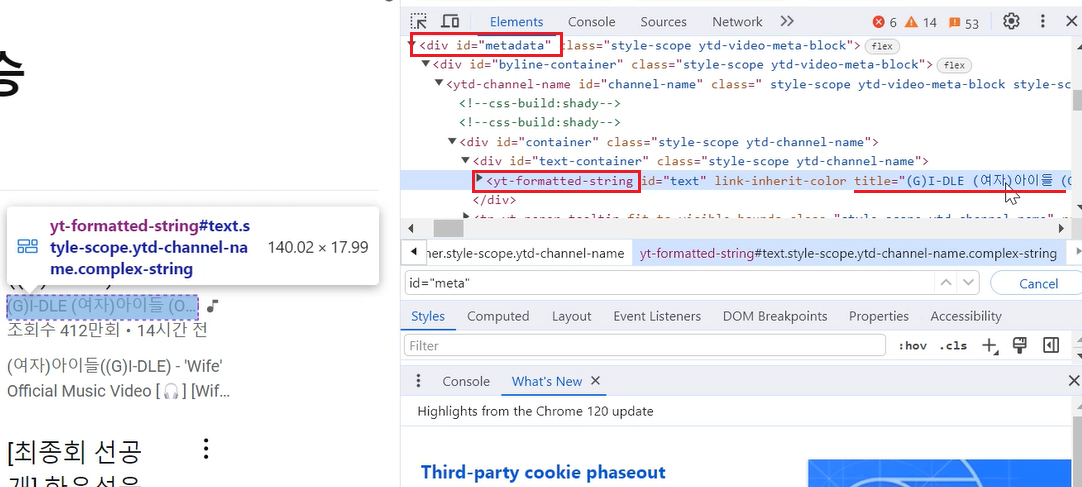
poster = txt.select_one('div#metadata yt-formatted-string#text')['title']
#링크
link = 'https://www.youtube.com' + a_tag['href']문자 형태인 views 변수를 정수형으로 변환하여 50만회 이상인지 체크합니다
50만회 이상이라면 영상 제목과 게시자, 링크를 태그를 이용하여 다시 추출합니다.
a_tag 찾기

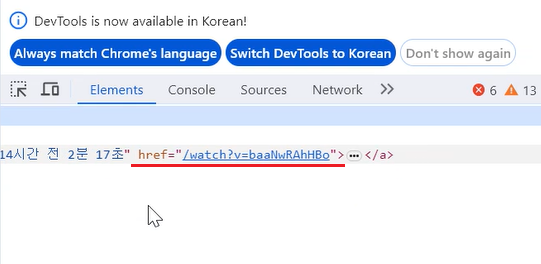
a_tag 안 제목과 링크 태그

게시자
href 속성 값에 도메인 네임이 없기 때문에 추가해줘야 합니다
엑셀에 행 추가
#현재 시간을 이용하여 문자열 만들기
d = datetime.datetime.now()
date = f'{d.year}년 {d.month}월 {d.day}일 {d.hour}시 인기 급상승 동영상'
ws.append([date, title, poster, link])
엑셀에 저장
wb.save("유튜브인기급상승동영상.xlsx")
이제 조회수가 50만회 이상인 유튜브 인기 급상승 동영상의 정보만 엑셀에 저장하게 되었습니다
그런데 문제가 있었습니다!
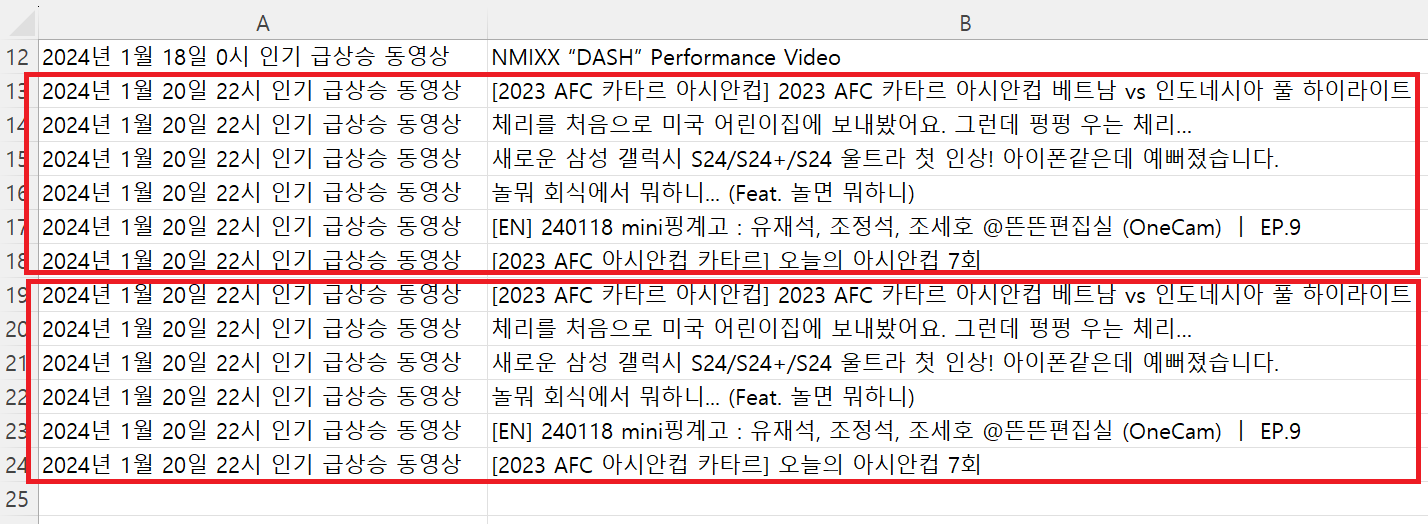
바로 같은 시간대에 웹 스크랩을 반복 시도하면 중복되는 row가 생기는 것입니다!!
중복 저장 방지
#date는 현재 날짜 시간
#date = f'{d.year}년 {d.month}월 {d.day}일 {d.hour}시 인기 급상승 동영상'
if not os.path.isfile("유튜브인기급상승동영상.xlsx"):
title_list = []
else:
xl = pd.read_excel('유튜브인기급상승동영상.xlsx')
#현재와 같은 날 같은 시간인 행의 영상 제목만 추출
title_list = set(xl[xl['시간'] == date]['영상 제목'])같은 시간대에 같은 제목을 가진 유튜브 동영상은 중복하여 추가되지 않도록
pandas 라이브러리를 사용하여 조건을 넣겠습니다.
세트 자료형으로 만들어 in 연산을 더 빠르게 진행할 수 있도록 하겠습니다
set, list의 in 성능 비교
[Python] List와 Set에서의 in 연산자 성능 비교하기.
in 연산자를 쓸 때는 set으로 바꿔서 쓰면 빠르다. List에서 in 연산자를 사용하면 사실 상 for문을 한번 도는 것이기 때문에 선형 시간인 O(n)의 시간 복잡도를 가집니다. 제 주변에서 이를 모르고 사
kyleyj.tistory.com
조건 추가
title이 title_list 안에 없다면 추가
title = a_tag['title']
#같은 날짜, 시간대에 동일한 이름이 있다면 업데이트 하지 않는다
if title in title_list:
pass
else:
#게시자
poster = txt.select_one('div#metadata yt-formatted-string#text')['title']
#링크
link = 'https://www.youtube.com' + a_tag['href']
print(title)
ws.append([date, title, poster, link])
결과


중복제외를 위해 다시 한 번 더 해보겠습니다


깃허브
https://github.com/stonegyoung/WebScraping
GitHub - stonegyoung/WebScraping: selenium을 사용한 구글 이미지 스크래핑자동화 프로그램입니다.
selenium을 사용한 구글 이미지 스크래핑자동화 프로그램입니다. Contribute to stonegyoung/WebScraping development by creating an account on GitHub.
github.com
'Python' 카테고리의 다른 글
| 정규식(regular expression) (0) | 2024.04.15 |
|---|---|
| [Python] 힙 (1) | 2024.02.05 |
| Selenium 사용하여 웹 자동화하기3- 뉴스 기사 스크랩 (5) | 2024.01.17 |
| Selenium 사용하여 웹 자동화하기2 (2) | 2024.01.16 |
| Selenium 사용하여 웹 자동화하기1 (0) | 2024.01.15 |