728x90
참고
https://pandas.pydata.org/docs/reference/api/pandas.concat.html
pandas.concat — pandas 2.2.3 documentation
If True, do not use the index values along the concatenation axis. The resulting axis will be labeled 0, …, n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index
pandas.pydata.org
1. concat: 단순 연결
2. merge: 기준 컬럼을 기준으로 연결
실습을 위한 라이브러리 임포트
import numpy as np
import pandas as pd
pd.concat(): 행 또는 열 방향으로 합침

pd.concat() 파라미터
- ignore_index: 기존 index 그대로/새롭게
False면 기존(디폴트), True면 새롭게
- verify_integrity: index가 중복되는지 확인
False면 중복 돼도 괜찮(디폴트), True면 에러 뜸
- axis
axis=0 위아래로 합침(디폴트) axis=1 옆으로 합침
- join: 컬럼명이 다를 때
join='outer' 합집합으로(디폴트)
join='inner' 교집합으로(동일한 컬럼만)
데이터
# https://pandas.pydata.org/docs/reference/api/pandas.concat.html
s1 = pd.Series(['a', 'b'])
s2 = pd.Series(['c', 'd'])
# 모두 디폴트 값으로(기존 index 그대로, index 중복 돼도 괜찮, 위아래로 합침, 합집합)
pd.concat([s1, s2])
# ignore_index=True 인덱스 새롭게 바꿈
pd.concat([s1, s2], ignore_index=True)
# verify_integrity=True 인덱스 중복되면 에러
pd.concat([s1, s2], verify_integrity=True)
# axis=1 옆으로 합침
pd.concat([s1, s2], axis=1)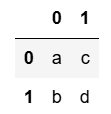
데이터 수가 다를 때 (NaN으로 채워짐)
s3 = pd.Series(['e','f','g'])
pd.concat([s2,s3], axis=1)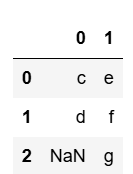
컬럼명이 다른 경우
df1 = pd.DataFrame([['a', 1], ['b', 2]],
columns=['letter', 'number'])
df2 = pd.DataFrame([['c', 3], ['d', 4]],
columns=['letter', 'n'])
# 합집합으로(default임) join='outer'
pd.concat([df1, df2], join='outer')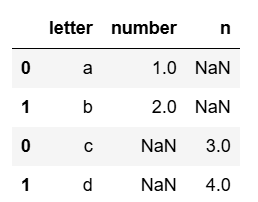
# 교집합으로 join='inner'
pd.concat([df1, df2], join='inner')
'빅데이터 공부' 카테고리의 다른 글
| 데이터 복사하기 (0) | 2025.02.27 |
|---|---|
| [Pandas] 데이터 병합하기 - merge (0) | 2025.02.19 |
| [Pandas] 데이터 변형하기 - stack, unstack (2) | 2024.12.08 |
| [Pandas] 데이터 변형하기 - pivot, pivot_table (0) | 2024.12.07 |
| [Pandas] 데이터 변형하기 - groupby (0) | 2024.10.22 |