2024.10.22 - [빅데이터 공부] - [Pandas] 데이터 변형하기 - groupby
[Pandas] 데이터 변형하기 - groupby
1. groupby()2. pd.pivot(), pd.pivot_table()3. stack(), unstack() 실습을 위한 라이브러리 임포트import numpy as npimport pandas as pdimport seaborn as sns 팁 데이터 사용tips = sns.load_dataset('tips') 데이터 살펴보기tips.head()ti
dogfoot1.tistory.com
1. groupby()
2. pd.pivot(), pd.pivot_table()
3. stack(), unstack()
실습을 위한 라이브러리 임포트
import numpy as np
import pandas as pd
참고
https://pandas.pydata.org/docs/user_guide/reshaping.html
Reshaping and pivot tables — pandas 2.2.3 documentation
Reshaping and pivot tables pandas provides methods for manipulating a Series and DataFrame to alter the representation of the data for further data processing or data summarization. Data is often stored in so-called “stacked” or “record” format. In
pandas.pydata.org

특징
- 데이터의 가독성이 떨어질 때 사용한다.
- index, column, value를 지정할 수 있다.
- pivot_table은 aggfunc도 지정 가능
pivot과 pivot_table의 차이
| pivot | pivot_table | |
| 인덱스가 2개 이상인 경우 | 에러 | 계산 가능 |
| 컬럼이 2개 이상인 경우 | 에러 | 계산 가능 |
| 여러 값이 있는 경우 | 에러 | 계산 가능 |
데이터 프레임 생성
df = pd.DataFrame({
"r1": ["one", "one", "two", "three"] * 6,
"r2": ["A", "B", "C"] * 8,
"r3": ["foo", "foo", "foo", "bar", "bar", "bar"] * 4,
"r4": np.random.randn(24)
})
df
pivot(), pivot_table()
둘의 차이에 맞춰 예제를 보겠다.
1. 여러 값이 있을 때
r1을 인덱스로, r2를 컬럼으로, r4를 value로 할 때
r1이 one이고, r2가 A인 값이 여러 개라면
# 중복값 있을 때 : index, columns이 같은 게 중복됨
df[(df['r1'] == 'one') & (df['r2'] == 'A')]
- pivot
# 에러
# index: r1, columns: r2, values: r4
pd.pivot_table(df, index='r1', columns='r2', values='r4')
- pivot_table
# index: r1, columns: r2, values: r4
pd.pivot_table(df, index='r1', columns='r2', values='r4')
여러 값이 존재할 때 pivot에서는 에러가 나지만 pivot_table에서는 에러가 나지 않는다
pivot_table은 r1이 one이고, r2가 A인 것들의 평균을 내서 넣어준다
(0.607863-0.236812-1.273399+0.459466)/4 = -0.110721
그러면 평균 말고, 다른 값으로 바꾸고 싶다면
aggfunc을 사용할 수 있다.
# index: r1, columns: r2, values: r4 + aggfunc 시 합계로
pd.pivot_table(df, index='r1', columns='r2', values='r4', aggfunc=np.sum)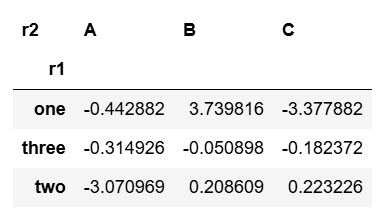
0.607863-0.236812-1.273399+0.459466 = -0.442882
2. 인덱스가 두 개 이상일 때
- pivot
# 에러
pd.pivot(df, index=['r1', 'r3'], columns='r2', values='r4')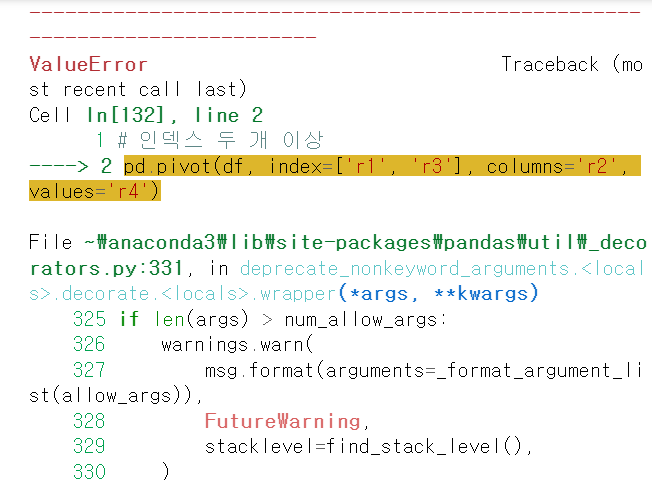
- pivot_table
pd.pivot_table(df, index=['r1', 'r3'], columns='r2', values='r4')
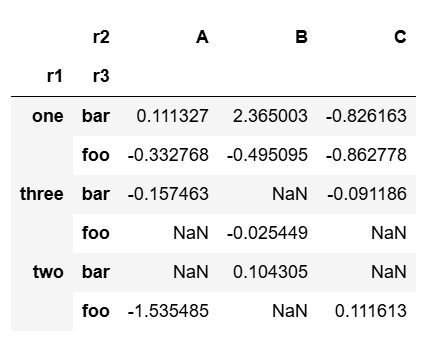
없으면 NaN으로 채워진다.
이곳에서도 여러 값이 나온다면, 평균을 내 값이 채워진다.
r1이 one이고, r2가 A, r3가 foo인 것을 보면 여러 값이 나온다.
df[(df['r1']=='one') & (df['r2']=='A') & (df['r3']=='foo')]
(0.607863-1.273399)/2 = 0.332768
pivot_table에서는 평균으로 대체한다.
3. 컬럼이 두 개 이상일 때
- pivot
# 에러
pd.pivot(df, index='r1', columns=['r2', 'r3'], values='r4')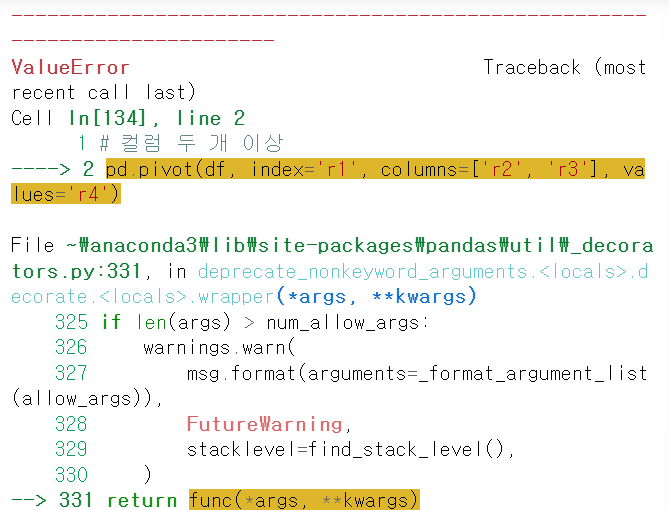
- pivot_table
pd.pivot_table(df, index='r1', columns=['r2', 'r3'], values='r4')
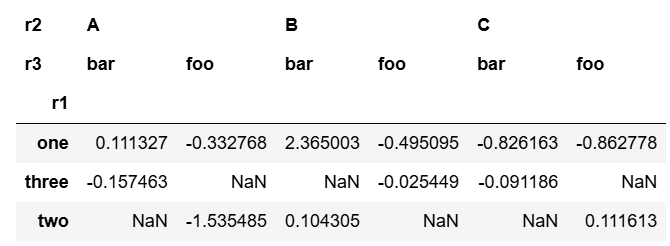
없으면 NaN으로 채워진다.
똑같이 r1이 one이고, r2가 A, r3가 foo인 것은 -0.332768이 된다.
'빅데이터 공부' 카테고리의 다른 글
| [Pandas] 데이터 병합하기 - concat (0) | 2025.02.17 |
|---|---|
| [Pandas] 데이터 변형하기 - stack, unstack (1) | 2024.12.08 |
| [Pandas] 데이터 변형하기 - groupby (0) | 2024.10.22 |
| [Pandas] DataFrame (0) | 2024.07.14 |
| PCA (2) | 2024.01.09 |