https://pandas.pydata.org/docs/reference/api/pandas.merge.html
pandas.merge — pandas 2.2.3 documentation
If False, avoid copy if possible. Note The copy keyword will change behavior in pandas 3.0. Copy-on-Write will be enabled by default, which means that all methods with a copy keyword will use a lazy copy mechanism to defer the copy and ignore the copy keyw
pandas.pydata.org
1. concat: 단순 연결
2. merge: 기준 컬럼을 기준으로 연결
실습을 위한 라이브러리 임포트
import numpy as np
import pandas as pd
pd.merge(): 기준 컬럼을 가지고 연결
SQL의 JOIN처럼 동작

pd.merge() 파라미터
- 기준 컬럼이 같을 때: on / 기준 컬럼이 다를 때: left_on & right_on
on = '기준 컬럼'
left_on = '왼쪽 기준이 될 컬럼'
right_on = '오른쪽 기준이 될 컬럼'
- how
1. 'inner'(디폴트): 기준 컬럼이 겹치는 것만
2. 'left', 'right': 왼쪽/오른쪽을 기준으로
3. 'outer': 둘 다 보이도록
4. 'cross': 모든 가능한 조합 생성(카테시안 조인). 기준 컬럼이 없어 'on' 파라미터 지정 안됨
- 인덱스를 기준으로 병합할 때 : left_index, right_index
데이터
# https://pandas.pydata.org/docs/reference/api/pandas.merge.html
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
on: 기준 컬럼이 같을 때 사용
# value 컬럼을 기준으로 inner join
pd.merge(df1, df2, on='value')
# on 없어도 알아서 동일한 컬럼으로 해줌
pd.merge(df1, df2)
pd.merge(df1, df2, on='value', how='left')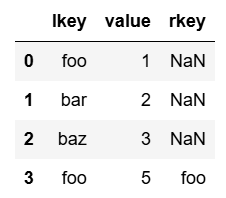
pd.merge(df1, df2, on='value', how='right')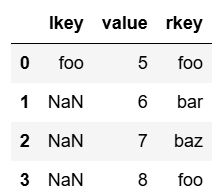
pd.merge(df1, df2, on='value', how='outer')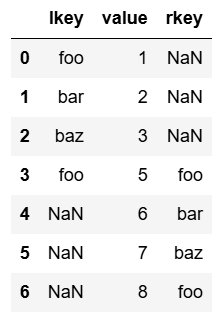
pd.merge(df1, df2, how='cross')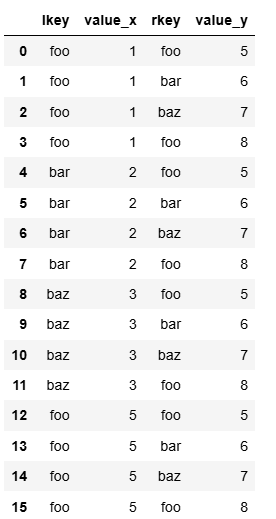
left_on, right_on: 기준 컬럼이 다를 때 사용
pd.merge(df1, df2, left_on='lkey', right_on='rkey')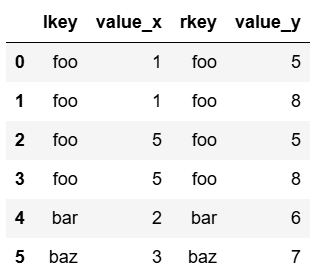
인덱스를 join 키로 사용
# value 컬럼이 인덱스가 됨
df1.set_index('value')
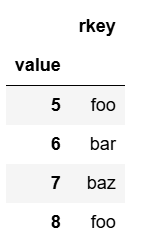
df2.set_index('value')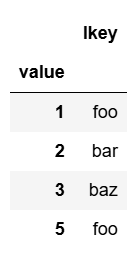
# left_index=True, right_index=True -> join 키로 인덱스를 사용
pd.merge(df1.set_index('value'), df2.set_index('value'), left_index=True, right_index=True)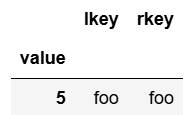
하나만 인덱스, 하나는 컬럼
# left_index=True, right_index=True -> join 키로 인덱스를 사용
pd.merge(df1.set_index('value'), df2, left_index=True, right_on='value')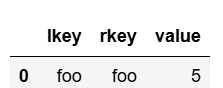
'빅데이터 공부' 카테고리의 다른 글
| numpy를 이용한 k-평균 클러스터링 (0) | 2025.03.21 |
|---|---|
| 데이터 복사하기 (0) | 2025.02.27 |
| [Pandas] 데이터 병합하기 - concat (0) | 2025.02.17 |
| [Pandas] 데이터 변형하기 - stack, unstack (1) | 2024.12.08 |
| [Pandas] 데이터 변형하기 - pivot, pivot_table (0) | 2024.12.07 |