1. groupby()
2. pd.pivot(), pd.pivot_table()
3. stack(), unstack()
실습을 위한 라이브러리 임포트
import numpy as np
import pandas as pd
import seaborn as sns
팁 데이터 사용
tips = sns.load_dataset('tips')
데이터 살펴보기
tips.head()
tips.info()groupby()
컬럼 값이 같은 것끼리 그룹화한다
# 성별로 묶기
group_sex = tips.groupby('sex')
# 객체를 리턴
group_sex
그룹의 속성이 보고 싶다면
groups()
group_sex.groups
groupby의 함수 활용
- count: 데이터 수
- size: 집단 별 크기
- sum: 합
- mean: 평균
- min, max: 최소값, 최대값
groupby 객체 뒤에 사용하면 된다
group_sex.count()

특정 컬럼만 지정해서 볼 수 있다
# DataFrame으로
group_sex.mean()[['total_bill']]
# Series로
group_sex.mean()['total_bill']

여러 개의 컬럼을 그룹화 할 수 있다
리스트로 묶어주기
# 성별, 담배 여부로 그룹화
tip_groups = tips.groupby(['sex', 'smoker'])
# groupby 객체로 리턴
tip_groups
groupby 함수 활용
tip_groups[['total_bill']].mean()
# index는 튜플 형태
tip_groups[['total_bill']].mean().index
loc로 원하는 인덱스만 추출
# index로 원하는 데이터만 추출 -> loc로
tip_groups[['total_bill']].mean().loc[('Male', 'Yes')]
tip_groups[['total_bill']].mean().loc['Male']
여러 집계 함수 한꺼번에 사용하기
agg(), aggregate()
pandas.core.groupby.DataFrameGroupBy.aggregate — pandas 2.2.3 documentation
Aggregate using one or more operations over the specified axis. When using engine='numba', there will be no “fall back” behavior internally. The group data and group index will be passed as numpy arrays to the JITed user defined function, and no altern
pandas.pydata.org
tips.groupby(['sex', 'smoker']).agg(['mean', 'min', 'max'])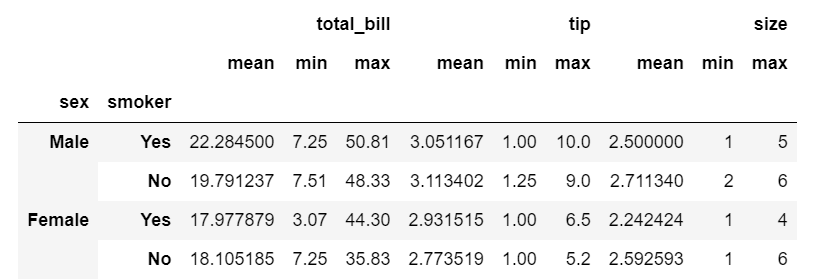
+ set_index()와 reset_index()
set_index(): 다중 groupby()와 비슷(하지만 그룹화 하진 않는다)
# 인덱스를 sex와 smoker로 지정
tips.set_index(['sex', 'smoker'], inplace=True)
tips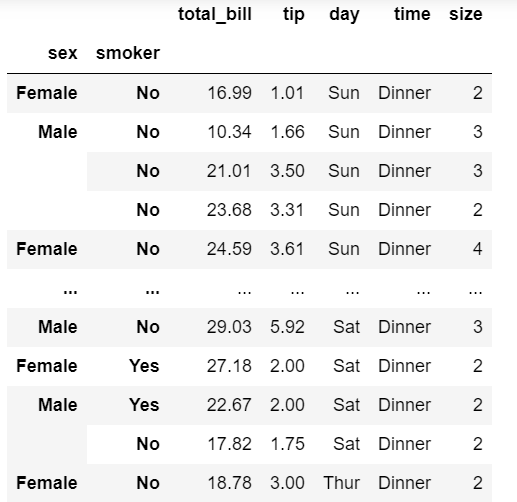
tips.loc[('Female', 'No')]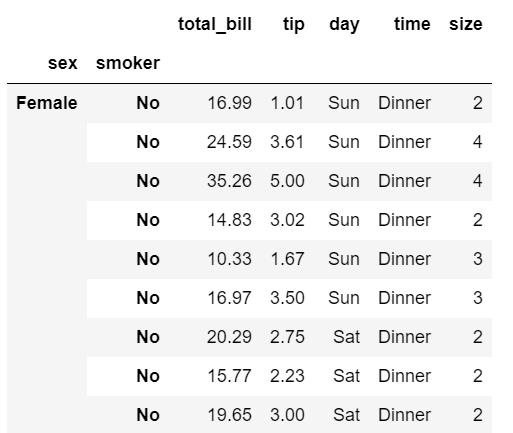
reset_index(): 기본 인덱스로 돌아간다
tips.reset_index(inplace=True)
tips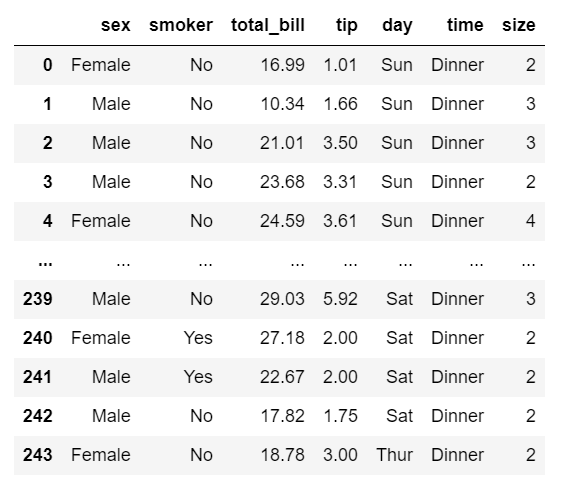
인덱스를 기준으로 groupby
level을 사용
# tips.groupby('sex').mean()과 같음
tips.set_index(['sex', 'smoker']).groupby(level=[0]).mean()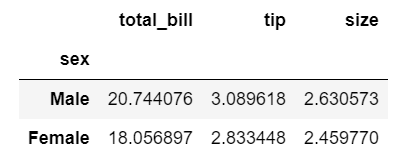
'빅데이터 공부' 카테고리의 다른 글
| [Pandas] 데이터 변형하기 - stack, unstack (1) | 2024.12.08 |
|---|---|
| [Pandas] 데이터 변형하기 - pivot, pivot_table (0) | 2024.12.07 |
| [Pandas] DataFrame (0) | 2024.07.14 |
| PCA (2) | 2024.01.09 |
| [빅데이터분석기사 실기] 제3유형-가설검정 (0) | 2024.01.08 |