필요 라이브러리 임포트
import numpy as np
import pandas as pd
1. 데이터프레임 만들기: pd.DataFrame()
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
자주 사용하는 파라미터
index: 인덱스명 지정
columns: 컬럼명 지정
- 딕셔너리 사용
key 값이 컬럼, value에 리스트 형태로 각 인덱스 값 넣기
pd.DataFrame({'a':[10,20], 'b':[20,40], 'c':[59,39]})
인덱스명을 지정하고 싶을 때: index=[]
pd.DataFrame({'a':[10,20], 'b':[20,40], 'c':[59,39]}, index=['s1', 's2'])
- 리스트 사용
pd.DataFrame([[1,2], [2,3], [45, 4]], ['s1', 's2', 's3'])
컬럼명을 지정하고 싶을 때: columns=[]
pd.DataFrame([[1,2], [2,3], [45, 4]], index=['s1', 's2', 's3'], columns=['a', 'b'])
2. 데이터프레임 불러오기: pd.read_csv()
pd.read_csv(filepath_or_buffer)
자주 사용하는 파라미터
sep: 데이터 구별자. 기본값은 ,
index_col: 인덱스로 사용할 컬럼 설정. 멀티 인덱스 가능
usecols: 사용할 컬럼만 설정
encoding: 사용할 인코딩
csv 다운
https://www.kaggle.com/datasets/contactprad/bike-share-daily-data
Bike Share Daily Data
This is a bike sharing data by Capitol system for year 2011-2012
www.kaggle.com
data = pd.read_csv('bike_sharing_daily.csv')
data.head()
# index_col 사용
data = pd.read_csv('bike_sharing_daily.csv', index_col='instant')
data.head()
# index_col로 multi index 만들기
data = pd.read_csv('bike_sharing_daily.csv', index_col=['instant', 'yr'])
data.head()
# usecols 사용
data = pd.read_csv('bike_sharing_daily.csv', usecols=['season', 'yr'])
data.head()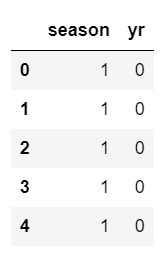
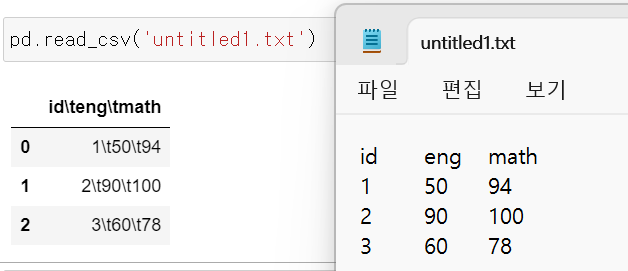
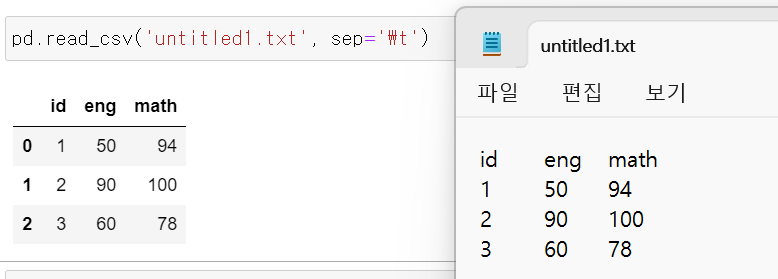
+ sep 사용
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
pandas.DataFrame — pandas 2.2.2 documentation
Dict can contain Series, arrays, constants, dataclass or list-like objects. If data is a dict, column order follows insertion-order. If a dict contains Series which have an index defined, it is aligned by its index. This alignment also occurs if data is a
pandas.pydata.org
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html#pandas.read_csv
pandas.read_csv — pandas 2.2.2 documentation
Character or regex pattern to treat as the delimiter. If sep=None, the C engine cannot automatically detect the separator, but the Python parsing engine can, meaning the latter will be used and automatically detect the separator from only the first valid r
pandas.pydata.org
'빅데이터 공부' 카테고리의 다른 글
| [Pandas] 데이터 변형하기 - pivot, pivot_table (0) | 2024.12.07 |
|---|---|
| [Pandas] 데이터 변형하기 - groupby (0) | 2024.10.22 |
| PCA (2) | 2024.01.09 |
| [빅데이터분석기사 실기] 제3유형-가설검정 (0) | 2024.01.08 |
| 비지도학습-클러스터링 (0) | 2024.01.08 |