빅데이터 분석 과정
1. 필요 패키지 임포트
2. 데이터 불러오기
3. 데이터 살펴보기
4. 데이터 전처리
5. 데이터 나누기
6. 데이터 분석 수행
7. 성능평가 및 시각화
1. 필요 패키지 임포트
import numpy as np
import pandas as pd
import sklearn빅분기 실기에서는 그래프가 안되는 것으로 알고 있습니다(아닐지도..)
2. 데이터 불러오기
df = pd.read_csv("경로")3. 데이터 살펴보기
데이터를 탐색한다.
-데이터 프레임의 구성
df.head()
-데이터 프레임 행, 열 수
df.shape
-데이터 프레임 컬럼 당 null값, 타입
df.info()
-데이터 프레임 기술 통계
#숫자형만
df.describe()
#오브젝트형도 함께
df.describe(include='all')
4. 데이터 전처리1 - 데이터 정제(결측값, 이상값)
결측값 확인 : isnull().sum()
df.isnull().sum()각 컬럼의 결측값 수를 보여준다
결측값이 있는 행 제거 : dropna()
# 데이터프레임 전체에서 결측값이 있는 행 모두 제거
new_df = df.dropna(axis=0)
# 데이터프레임 지정 컬럼에서 결측값이 있는 행 제거
new_df = df.dropna(subset='컬럼', axis=0)열 삭제 시 axis=1
결측값을 대체 : fillna()
-평균값 대체 mean()
dm = df['컬럼'].mean()
#방법1
df['컬럼'] = df['컬럼'].fillna(dm)
#방법2
df['컬럼'].fillna(dm, inplace=True)
-중앙값 대체 median()
dm = df['컬럼'].median()
#방법1
df['컬럼'] = df['컬럼'].fillna(dm)
#방법2
df['컬럼'].fillna(dm, inplace=True)
-최빈값으로 대체 mode()[0]
dm = df['컬럼'].mode()[0]
#방법1
df['컬럼'] = df['컬럼'].fillna(dm)
#방법2
df['컬럼'].fillna(dm, inplace=True)
-인접값으로 대체 method = 'ffill' / 'bfill'
#위의 값으로 대체
df['컬럼'].fillna(method='ffill', inplace=True)
#아래의 값으로 대체
df['컬럼'].fillna(method='bfill', inplace=True)
-그룹별 평균값으로 대체
grouped = df.groupby('그룹화할 컬럼')['집계함수를 적용할 컬럼']
df['컬럼'].fillna(grouped.transform('mean'), inplace=True)
이상값 확인 : IQR로
-그래프로 확인 : plot(kind = 'box')
df.plot(kind='box')박스플롯으로 확인
-이상값 제거 : drop()
q1 = df['컬럼'].quantile(0.25)
q3 = df['컬럼'].quantile(0.75)
iqr = q3 - q1
condition = (df['컬럼'] < q1 - 1.5 * iqr) | (df['컬럼'] > q3 + 1.5 * iqr)
df.drop(df.loc[condition].index, inplace = True)
https://beneagain.tistory.com/52
Pandas DataFrame : del / drop 행, 열 삭제, 특정행 삭제
https://benn.tistory.com/27 [데이터 분석] 파이썬 Pandas 행, 열 삭제 이번 글에서는 유명한 Iris 데이터셋을 사용하여 판다스를 사용해 원하지 않는 데이터를 삭제하는 방법을 정리해봤습니다. 먼저 판다
beneagain.tistory.com
-이상값 처리
q1 = df['컬럼'].quantile(0.25)
q3 = df['컬럼'].quantile(0.75)
iqr = q3 - q1
condition = (df['컬럼'] < q1 - 1.5 * iqr) | (df['컬럼'] > q3 + 1.5 * iqr)
df.loc[condition, '컬럼'] = 대체할 값
[Data] 데이터 전처리 - '이상치(Outlier)와 결측치(Missing Value) 처리하기
다양한 데이터를 접하면서 가장 고민이 되는 부분이 해당 데이터의 '이상치'와 '결측치'를 어떻게 처리하는지이기 때문에 이제부터 다양한 처리 방법에 대해 알아보자!
velog.io
4. 데이터 전처리2 - 데이터 변환
(데이터 인코딩, 단위 환산, 자료형 변환, 표준화, 정규화, 파생변수 생성)
데이터 인코딩
: 사람이 인지할 수 있는 형태의 데이터를 컴퓨터가 인지할 수 있는 수로 변환
레이블 인코딩, 원핫 인코딩
-레이블 인코딩1 : replace(), map()
df['인코딩할 컬럼'].replace({'컬럼데이터1':0, '컬럼데이터2':1, '컬럼데이터3':2}, inplace=True)
df['인코딩할 컬럼'] = df['인코딩할 컬럼'].map({'컬럼데이터1':0, '컬럼데이터2':1, '컬럼데이터3':2})컬럼데이터가 별로 없을 때 사용할 수 있다.
-레이블 인코딩1 : 싸이킷런의 LabelEncoder()
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
df['인코딩할 컬럼'] = le.fit_transform(df['인코딩할 컬럼'])
-원 핫 인코딩 : pd.get_dummies()
df = pd.get_dummies(df, columns=['인코딩할 컬럼1', '인코딩할 컬럼2'])
[Python] pd.get_dummies() :: One-Hot Encoding / 원핫인코딩
머신러닝에서 문자로 된 데이터는 모델링이 되지 않는 경우가 있다. 대표적으로 회귀분석은 숫자로 이루어진 데이터만 입력을 해야한다. 문자를 숫자로 바꾸어 주는 방법 중 하나로 One-Hot Encodin
mizykk.tistory.com
-표준화 : 싸이킷런의 MinMaxScaler()
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['컬럼'] = scaler.fit_transform(df[['컬럼']])
-정규화 : 싸이킷런의 StandardScaler()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['컬럼'] = scaler.fit_transform(df[['컬럼']])
데이터셋이 학습과 테스트로 이미 나뉘어져 있다면 fit()과 transform()을 각각 해야 한다
fit(): 변환 방법 학습
transform(): 데이터 변환
학습용 데이터셋에 : fit_transform()
테스트 데이터셋에 : transform()
X_train['컬럼'] = scaler.fit_transform(X_train[['컬럼']])
X_test['컬럼'] = scaler.transform(X_test[['컬럼']])
https://moruxz.tistory.com/108
[ML] fit_transform()과 transform()
1. fit_transform()과 transform()의 차이 2. train 데이터에 fit_transform()이 아니라 transform()을 사용한다면? 3. train데이터와 test데이터를 나누기 전에 one hot encoding 해도 될까? 4. pd.get_dummies()와 sklearn의 OneHotEn
moruxz.tistory.com
https://deepinsight.tistory.com/165
[scikit-learn] transform()과 fit_transform()의 차이는 무엇일까?
왜 scikit-learn에서 모델을 학습할 때, train dataset에서만 .fit_transform()메서드를 사용하는 건가요? TL;DR 안녕하세요 steve-lee입니다. 실용 머신러닝 A to Z 첫번 째 시간은 scikit-learn에서 자주 사용하는 tra
deepinsight.tistory.com
5. 데이터 나누기 - 싸이킷런의 train_test_split()
전처리를 마친 데이터를 학습용 데이터셋과 테스트용 데이터셋으로 분리한다.
혹은 검증을 위해 학습용 데이터셋을 학습용과 검증용으로 분리한다.
-학습용, 테스트용 데이터 분리
from sklearn.model_selection import train_test_split
X= df[['컬럼1', '컬럼2', '컬럼3']] #피처 넣기
y= df[['타겟변수']]
# X 데이터프레임의 20%는 테스트용, 80%는 학습용
X_train, X_test, y_train, y_test = (X, y, test_size = 0.2, random_state = 10, stratify = y)test_size 데이터셋 중 테스트 데이터셋 비율을 써준다.
random_state 테스트 데이터셋을 어떻게 고를지 설정. 정수를 써준다.
매번 똑같은 데이터셋이 생김
파라미터 없으면, 누를 때마다 랜덤한 데이터셋 생성됨
stratify 데이터 분포가 원래 데이터 분포와 동일하게 분리
-학습용, 검증용 데이터 분리(학습 데이터를 나눠야 할 때)
from sklearn.model_selection import train_test_split
x_tr, x_vl, y_tr, y_vl = train_test_split(X_train, y_train, test_size=0.2, random_state=10)6. 데이터 분석 수행
지도학습에서 문제가 출제됩니다.
지도학습 데이터 분석 기법
1. 분류 모형-의사결정나무, KNN, 서포트벡터머신, 랜덤포레스트, 로지스틱 회귀분석
2. 회귀 모형-선형회귀분석, 랜덤포레스트, 의사결정나무
-지도학습 알고리즘 선택
| 분류 | 의사결정나무 | from sklearn.tree import DecisionTreeClassifier |
| KNN | from sklearn.neighbors import KNeighborsClassifier |
|
| 서포트벡터머신(SVM) | from sklearn.svm import SVC | |
| 로지스틱 회귀분석 | from sklearn.linear_model import LogisticRegression |
|
| 랜덤포레스트 | from sklearn.ensemble import RandomForestClassifier |
|
| 회귀(예측) | 선형회귀분석 | from sklearn.linear_model import LinearRegression |
| 랜덤포레스트 | from sklearn.ensemble import RandomForestRegressor |
|
| 의사결정나무 | from sklearn.tree import DecisionTreeRegressor |
확실하게 사용 할 하나를 외워가는 것이 좋습니다. 만약 기억이 안난다면 dir() 을 사용하면 됩니다!!
import sklearn
from sklearn import *
print(dir(sklearn))
##########################
#예시: tree
import sklearn.tree
print(dir(sklearn.tree))
-분석을 수행 : fit() , predict()
#예시 의사결정나무
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state = 2022)
model.fit(X_train, y_train)
pred = model.predict(X_test)model은 위에서 임포트한 알고리즘에 따라 바뀐다.
동일한 분석을 위해 random_state는 넣어줘야 한다
7. 성능평가 - sklearn.metrics
문제에 어떤 것으로 성능평가를 하는지 나와있기 때문에 보고 하면된다
-지도학습(분류)의 성능 평가
#분류 성능
from sklearn.metrics import roc_auc_score
print(roc_auc_score(test_y, pred_y))accuracy_score(실제 y값, 모델이 예측한 y값)
-지도학습(회귀)의 성능 평가
from sklearn.metrics import mean_squared_error, r2_score
print(np.sqrt(mean_squared_error(y_test, y_pred))
print(r2_score(y_test, y_pred))
모르겠다면 dir() 사용
import sklearn.metrics
print(dir(sklearn.metrics))
<참고>
https://aitzone.tistory.com/29
[빅데이터분석기사] 작업 2유형 작성패턴 - 분류문제
빅데이터 분석기사의 2유형은 전체 100점 배점중 40점을 차지하는 한 문제가 나온다. 필답형 문제 (30점)이나 1유형 (30점)을 만점을 받을 자신이 있으면 날려도 되지만, 보통 그렇게 하기 힘든 부분
aitzone.tistory.com
[빅데이터분석기사] 작업형2 예시문제 (분류)
* 퇴근후딴짓 님의 강의를 참고하였습니다.* [ 문제 ] 아래는 백화점 고객의 1년간 구매 데이터이다. (가) 제공데이터 목록 1. y_train.csv : 고객의 성별데이터(학습용), csv형식의 파일 2. X_train.csv, X_te
inform.workhyo.com
https://www.youtube.com/watch?v=_GIBVt5-khk
https://www.youtube.com/watch?v=L6sSKf2sv0k
[빅데이터분석기사] 실기 2회 2유형 풀이(Python)
전자상거래 배송 데이터 제품 배송 시간에 맞춰 배송되었는지 예측모델 만들기 학습용 데이터 (X_train, y_train)을 이용하여 배송 예측 모형을 만든 후, 이를 평가용 데이터(X_test)에 적용하여 얻는
it-utopia.tistory.com
https://github.com/lovedlim/BigDataCertificationCourses
GitHub - lovedlim/BigDataCertificationCourses: 빅데이터 분석기사 실기 준비 자료
빅데이터 분석기사 실기 준비 자료. Contribute to lovedlim/BigDataCertificationCourses development by creating an account on GitHub.
github.com
저는 7회 시험을 봤습니다!!
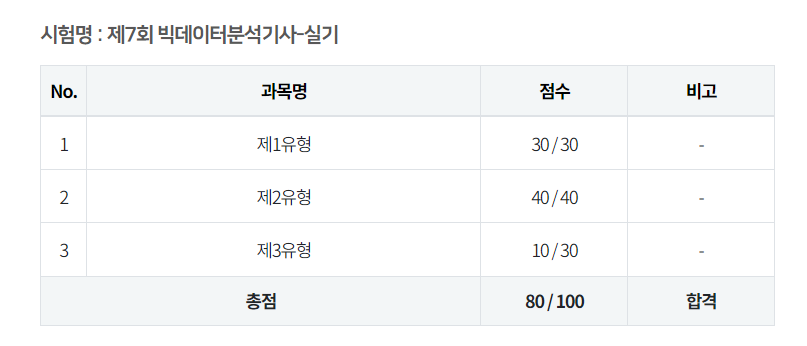
다행히 합격 예정입니다!!!!!!!!!!!
1단계
결측값 확인 후 처리 -> 검증 데이터 분리 -> 여러 모델 가지고 학습 후 평가
2단계
결측값 확인 후 처리 -> 인코딩 -> 검증 데이터 분리 -> 여러 모델 가지고 학습 후 평가
3단계
결측값 확인 후 처리 -> 인코딩(저는 라벨인코딩 했습니다) -> 스케일링 -> 검증 데이터 분리 -> 여러 모델 가지고 학습 후 평가
이렇게 하면서
인코딩 부분에서 특정 컬럼 뺐을 때
스케일링 부분에서 특정 컬럼 뺐을 때
하면서 모델 평가가 가장 잘 나온 모델로 선택하여
그 모델로 실제 문제도 학습하고 제출했습니다
꼭 실습을 따라해보고 모르겠으면 유튜브 강의를 보면 좋을 것 같습니다.
케글도 잘 활용하시고욥!!
모두 화이팅!!!

'빅데이터 공부' 카테고리의 다른 글
| [빅데이터분석기사 실기] 제3유형-가설검정 (0) | 2024.01.08 |
|---|---|
| 비지도학습-클러스터링 (0) | 2024.01.08 |
| 데이터 클리닝 (0) | 2023.11.29 |
| 판다스 기본 제공 메소드로 시각화하기 (2) | 2023.11.23 |
| DataFrame 다루기 (1) | 2023.10.26 |