개발자를 위한 실전 선형대수학(파이썬 3.10 버전 대응, 구글 코랩 실습 가능) | 마이크 X 코헨 - 교
개발자를 위한 실전 선형대수학(파이썬 3.10 버전 대응, 구글 코랩 실습 가능) | 복잡한 증명과 수식 없이 파이썬을 이용해 직관적으로 배우는 선형대수학 * 연습문제 + 해답 + 해설 강의, 무료 샘
product.kyobobook.co.kr
2024.01.08 - [빅데이터 공부] - 비지도학습-클러스터링
비지도학습-클러스터링
클러스터링 좀 더 의미있는 인사이트를 추출하기 위해 유사한 데이터들을 클러스터(집단)으로 묶어주는 것 비지도학습 중 하나(정답이 주어지지 않은 상태에서 스스로 찾아내는 것) 정답을 주
dogfoot1.tistory.com
데이터 공간에서 임의의 k개 중심점 초기화
-> 각 데이터와 중심점의 유클리드 거리 계산
-> 가장 가까운 중심점 그룹에 할당
-> 각 중심점을 할당된 모든 데이터 관측치의 평균으로 갱신
화살표 반복
필요 라이브러리 임포트
import numpy as np
import matplotlib.pyplot as plt
데이터 공간에서 임의의 k개 중심점 초기화
k: 3,
data: 2개의 피처를 가진 150개의 무작위 값의 데이터. (150,2)의 shape
k = 3
data = np.random.randn(150,2)
plt.scatter()를 이용하여 시각화를 해보겠습니다.
plt.scatter(data[:, 0], data[:, 1])
plt.xticks([], []) # 눈금 없애기
plt.yticks([], []) # 눈금 없애기
plt.show()
중심점 구하기
150개의 데이터에서 3개의 값 비복원 추출
# https://rfriend.tistory.com/548 -> n개의 데이터에서 k 개의 데이터 추출(replace 복원/비복원)
# k개 뽑기(인덱스)
ridx = np.random.choice(len(data), k, replace=False) # 150개의 데이터에서 3개의 데이터 비복원 추출
이 인덱스의 데이터를 중심점으로 사용합니다.
centroids = data[ridx] # data[[65, 143, 75]]
중심점은 빨간색으로 표시해서 시각화해보겠습니다.
plt.scatter(data[:, 0], data[:, 1])
plt.scatter(centroids[:,0], centroids[:,1], c='red', s=100)
plt.xticks([], []) # 눈금 없애기
plt.yticks([], []) # 눈금 없애기
plt.show()각 데이터와 중심점의 유클리드 거리 계산
유클리드 거리 계산 식은 각 원소끼리의 차이를 구하고 제곱한 뒤, 그 합의 제곱근을 구하는 방식
예시)
먼저 150개의 데이터와 3개의 중심점 사이의 각 거리를 넣을 dists 변수를 0으로 초기화해줍니다.
dists = np.zeros((len(data), k)) # (150,3)의 shape
반복문으로 k개의 중심점을 돌면서
(150,2)의 데이터와 중심점의 유클리드 거리를 계산하고, dists 변수에 넣어줍니다.
# axis=0 열끼리 더하기, axis=1 행끼리 더하기
for i in range(k):
dists[:, i] = np.sum((data - centroids[i])**2, axis=1) # sqrt 안해도 비교할 수 있으니까dists의 각 i열은 centroids[i] 와의 거리를 나타낸다
각 데이터 관측치를 가장 가까운 거리의 그룹에 할당
argmin -> 가장 작은 값의 인덱스를 반환
groupidx = np.argmin(dists, axis=1) # 각 행에서 가장 작은 값을 가진 인덱스를 반환
시각화를 해보겠습니다
for i, color in enumerate(['red','green', 'blue']):
plt.scatter(centroids[i,0], centroids[i,1], marker='X', c=color, s=200, label=f'{i}')
plt.scatter(data[groupidx==i, 0], data[groupidx==i, 1], c=color)
plt.xticks([], []) # 눈금 없애기
plt.yticks([], []) # 눈금 없애기
plt.legend()
plt.show()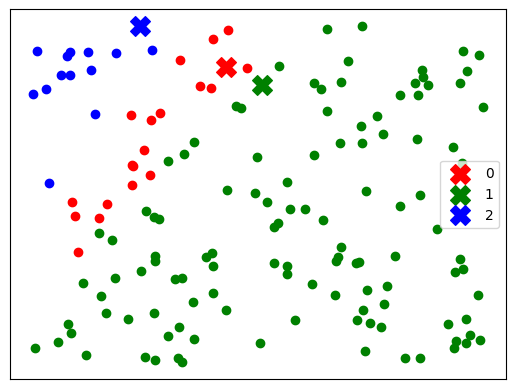
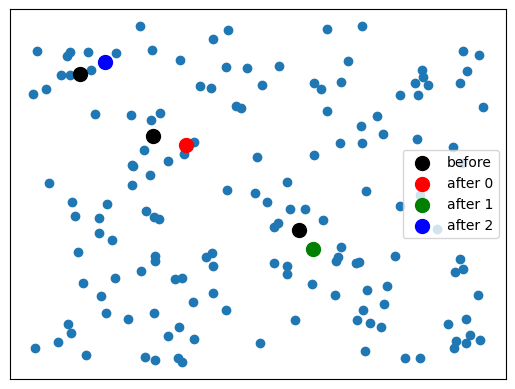
각 중심점을 할당된 모든 데이터 관측치의 평균으로 갱신
이제 다시 중심점을 할당하겠습니다.
for i in range(k):
centroids[i] = np.mean(data[groupidx==i],axis=0) # x는 x끼리, y는 y끼리의 평균
시각화를 해보겠습니다
plt.scatter(data[:, 0], data[:, 1])
for i in range(k):
plt.scatter(centroids[i,0], centroids[i,1], c='red', s=100)
plt.xticks([], []) # 눈금 없애기
plt.yticks([], []) # 눈금 없애기
plt.show()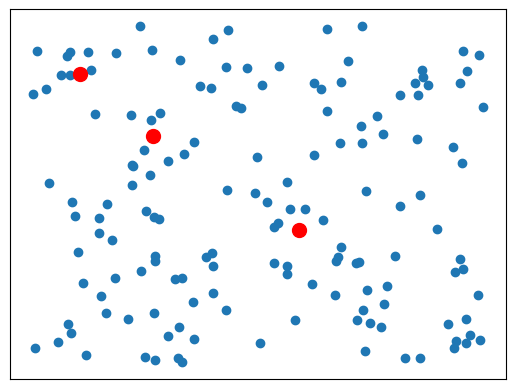
반복
data = #
k = #
ridx = np.random.choice(len(data),k, replace=False)
centroids = data[ridx]
# 거리 계산
dists = np.zeros((len(data),k))
for i in range(k):
dists[:,i] = np.sum((data-centroids[i])**2, axis=1)
# 제일 작은 값의 인덱스
groupidx = np.argmin(dists, axis=1)
# 평균 구하고 중심점 다시 설정
for i in range(k):
centroids[i] = np.mean(data[groupidx==i], axis=0)
'빅데이터 공부' 카테고리의 다른 글
| 데이터 복사하기 (0) | 2025.02.27 |
|---|---|
| [Pandas] 데이터 병합하기 - merge (0) | 2025.02.19 |
| [Pandas] 데이터 병합하기 - concat (0) | 2025.02.17 |
| [Pandas] 데이터 변형하기 - stack, unstack (1) | 2024.12.08 |
| [Pandas] 데이터 변형하기 - pivot, pivot_table (0) | 2024.12.07 |