Pytorch_Study/iris 인공신경망으로 만들기.ipynb at master · stonegyoung/Pytorch_Study
Pytorch 공부. Contribute to stonegyoung/Pytorch_Study development by creating an account on GitHub.
github.com
iris 데이터 로드
sklearn의 데이터셋을 사용합니다.
# 피처 4개
from sklearn.datasets import load_iris
load_iris()

'data'와 'target'을 사용
X = load_iris().data
y = load_iris().target
학습과 검증을 위해 train, test 데이터셋으로 분리
sklearn의 train_test_split()을 이용합니다.
from sklearn.model_selection import train_test_split
train_X, test_X = train_test_split(X, test_size=0.2, random_state=123)
train_y, test_y = train_test_split(y, test_size=0.2, random_state=123)
잘 나눠졌는 지 확인
len(train_X), len(test_X), len(train_y), len(test_y)
타입 확인
type(train_y)
train_test_split()은 넘파이를 반환합니다
넘파이 텐서로 바꾸기
torch.tensor() / torch.from_numpy()를 사용합니다.
torch_train_X = torch.tensor(train_X)
torch_train_y = torch.tensor(train_y)
torch_test_X = torch.tensor(test_X)
torch_test_y = torch.tensor(test_y)
numpy to tensor
1. torch.tensor()

2. torch.from_numpy()

+ tensor to numpy
.numpy()

PyTorch에서는 기본적으로 torch.tensor()를 사용하면 생성된 텐서의 데이터 타입이 torch.float64가 된다.
반면, PyTorch 모델의 파라미터는 torch.float32로 초기화된다.
-> 이로 인해 입력 데이터와 모델 파라미터 간에 데이터 타입이 맞지 않아 오류가 발생할 수 있습니다.
데이터 타입 변환
type()을 사용합니다
train_X = torch_train_X.type(torch.float32)
train_y = torch_train_y.type(torch.long)
test_X = torch_test_X.type(torch.float32)
test_y = torch_test_y.type(torch.long)
모델 만들기
import torch
import torch.nn as nn
분류 모델을 만들 때 클래스(카테고리)의 수 확인
train_y.unique()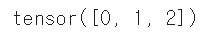
모델의 마지막 아웃풋 크기는 3이 되겠군요
iris 데이터는 컬럼이 4개이기 때문에
저는 4 -> 128 -> 64 -> 3 이 되는 인공신경망을 만들겠습니다.
nn.Module을 사용하여 클래스를 만들겠습니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 3)
self.afunc = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.afunc(x)
x = self.fc2(x)
x = self.afunc(x)
x = self.fc3(x)
return x
모델 정의
model = Net()
model
모델이 잘 작동하는 지 확인
(배치 사이즈, 인풋 크기) 를 모델에 넣을 때
(배치 사이즈, 아웃풋 크기) 로 나오면 됩니다.
# (4개의 컬럼을 가진 10개의 데이터)
data = torch.rand(10, 4)
model(data).shape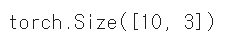
모델 학습
import torch.optim as optim
최적화 함수, 학습률, 손실 함수, 에폭 정의
# 최적화함수, 학습률
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 손실함수
criterion = nn.CrossEntropyLoss()
# 에폭
epochs = 100
모델 학습
# 시각화를 위한 loss값 저장 리스트
loss_list = []
for epoch in range(epochs):
# 학습할 때마다 기울기 초기화
optimizer.zero_grad()
# 순전파
y_pred = model(train_X)
# 손실함수 계산
loss = criterion(y_pred, train_y)
# loss 표시
print(f'epoch: {epoch+1} loss: {loss}')
loss_list.append(loss.item())
# 역전파
loss.backward()
# 파라미터 업데이트
optimizer.step()
loss 시각화
import matplotlib.pyplot as plt
plt.plot(range(epochs), loss_list)
plt.show()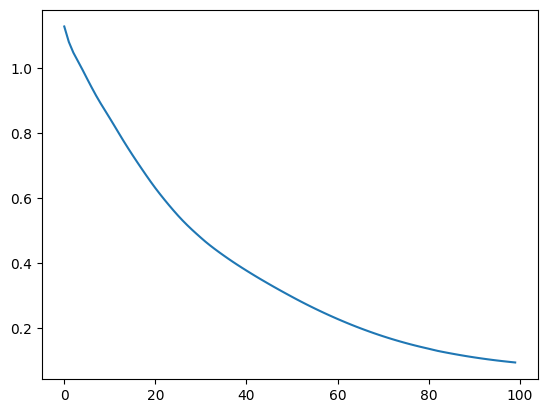
모델 검증
# 모델을 평가 모드로 전환
model.eval()
correct = 0 # 맞은 개수
total = len(test_y) # 전체 test 개수
with torch.no_grad(): # 역전파 방지 기울기 계산 비활성화
y_pred = model(test_X) # 테스트 데이터로 예측
result = y_pred.max(dim=1)[1] # 3가지 카테고리 중 값이 가장 큰 인덱스
correct = sum(result == test_y).item() # 단일 텐서에서 값만 뽑기 (여러 값이 들어있는 텐서는 tolist()나 numpy()로 바꿔야 됨)
accuracy = correct / total * 100
print(f'accuracy: {accuracy}')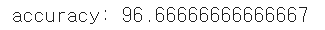
y_pred.max(dim=1)[1]에 대해서 자세히 설명해보겠습니다.
y_pred = model(test_X) # (30, 3) 텐서 반환
우리는 3가지 카테고리 중 가장 높은 값 하나를 반환해야 합니다.
-> max()를 사용하여 확인
dim = 0은 각 열에서 max를 찾고
dim = 1은 각 행에서 max를 찾습니다

y_pred.max(dim=1)을 하면 최대값들과 그 최대값이 있는 인덱스를 반환합니다.

우리는 인덱스가 필요하기 때문에 [1]을 가져옵니다.
모델 저장하기
-> 가중치만 저장하기
torch.save(model.state_dict(), 'pth 파일 이름을 포함한 경로')
가중치만 저장한 모델 불러오기
모델 구조 정의
# 모델 구조 정의
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 3)
self.afunc = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.afunc(x)
x = self.fc2(x)
x = self.afunc(x)
x = self.fc3(x)
return x
load_model = Net()
모델 가져오기
# 모델 불러오기
load_model.load_state_dict(torch.load('iris.pth'))'Pytorch' 카테고리의 다른 글
| [파이토치] 이미지 데이터 전처리/증강 (1) | 2024.12.28 |
|---|---|
| [파이토치] CNN (0) | 2024.12.26 |
| [파이토치] 모델 학습하기 (0) | 2024.12.23 |
| [파이토치] 모델 만들기 (1) | 2024.12.15 |
| [파이토치] 기본2 (0) | 2024.08.01 |