728x90
print(sr2[[2,3]]) #숫자 인덱스에 sr2[2], sr2[3] 출력
print(sr2[['2','3']]) #문자열 인덱스에 sr2['2'], sr2['3'] 출력판다스는 행과 열로 구성된 테이블 형식의 데이터를 다루는 데이터 분석에 많이 사용되는 패키지이다.
변수가 1개일 경우에는 시리즈(Series), 변수가 2개 이상이면 데이터프레임(Data Frame) 객체를 사용한다.
판다스 패키지 추가
import pandas as pd
Series: 1차원 배열 형태의 구조로, 인덱스와 데이터가 있어 파이썬 딕셔너리와 유사하다.
배열의 각 원소에는 서로 다른 자료형을 넣을 수 있고, 다차원 배열도 원소로 넣을 수 있다.
DataFrame: 2차원 테이블 형태의 구조로, 여러 열과 행을 가지며 열은 서로 다른 자료형을 가질 수 있다.
시리즈 객체 생성하기: pd.Series()
sr1=pd.Series([1,2,3,4,5])
print(sr1)
print(sr1.index)
print(sr1.values)
인덱스를 설정하지 않으면 0부터 시작하는 숫자 인덱스가 디폴트이다.
시리즈 객체의 인덱스 생성: index=
문자열 인덱스를 추가할 수 있다.
sr2=pd.Series([1,2,[10,20,30,40],"hi",1.3], index=['1','2','3','4','5'])
print(sr2[1]) #(기본)숫자 인덱스. 0부터 시작
print(sr2['1']) #문자열 인덱스. 내가 지정출력결과
2
1
오류
인덱스의 크기가 시리즈의 행 수와 같아야 합니다.
sr2=pd.Series([1,2,3,"hi",1.3], index=[1,2,3,4]) #오류
시리즈 원하는 원소 출력
여러 원소를 한 번에 선택할 수 있고, 범위로도 선택할 수 있다.
범위 선택 시, 숫자 인덱스는 끝 값-1까지, 문자열 인덱스는 끝 값도 포함된다.
sr2=pd.Series([1,2,[10,20,30,40],"hi",1.3], index=['a','b','c','d','e'])
print(sr2[[2,3]]) #sr2[2], sr2[3] 값 출력
print(sr2[['a','b']]) #sr2['a'], sr2[b] 값 출력
print(sr2[1:3]) #숫자 인덱스 1~2까지 값 출력
print(sr2['a':'c']) #문자열 인덱스 'a'~'c'까지 값 출력
데이터프레임 객체 생성: pd.DataFrame()
1. 2차원 리스트를 사용
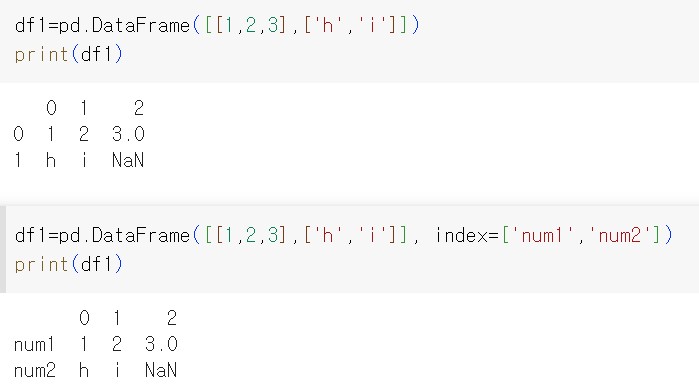
df1=pd.DataFrame([[1,2,3],['h','i']])
print(df1)
2. 딕셔너리를 사용
dic={'alphabet':['a','b','c'],
'num':[1,2,3]}
df2=pd.DataFrame(dic)
print(df2)
오류
딕셔너리의 value가 리스트라면 크기가 같아야합니다.
dic={'alphabet':['a','b','c'],
'num':[1,2]}
print(dic)
df2=pd.DataFrame(dic) #오류
데이터 프레임 객체에 인덱스 추가 index=
데이터 프레임 객체에 컬럼명 설정 columns=
데이터 프레임 객체의 인덱스와 컬럼명 변경: rename()
rename(columns={원래 컬럼1:바꿀 컬럼1, 원래 컬럼2:바꿀 컬럼2, ...})
rename(index={원래 인덱스1:바꿀 인덱스1, 원래 인덱스2:바꿀 인덱스2, ...})

inplace=True 옵션이 생략되면, 새로운 객체를 생성해서 반환한다.
df1=pd.DataFrame([[1,2,3],['h','i']], index=['num1','num2'])
print(df1)
df1.rename(columns={0:'a',1:'b',2:'c'}) #df1 변경 안됨
print(df1)
df1.rename(columns={0:'a',1:'b',2:'c'},inplace=True) #df1 변경 됨
print(df1)
'빅데이터 공부' 카테고리의 다른 글
| 데이터 클리닝 (0) | 2023.11.29 |
|---|---|
| 판다스 기본 제공 메소드로 시각화하기 (2) | 2023.11.23 |
| DataFrame 다루기 (2) | 2023.10.26 |
| Pandas DataFrame의 데이터 전처리 (0) | 2023.07.12 |
| 넘파이(Numpy) (0) | 2023.06.03 |